Stop babysitting
AI agents.
The first dark factory that works. MergeFoundry interviews requirements, plans dependency-gated task graphs, dispatches parallel agents in isolated worktrees, cross-model reviews every diff, certifies with 6 drift auditors, and merges through an AI-powered queue. You wake up to certified, production-ready PRs.
AI tools made coding 10x faster.
Everything else became the bottleneck.
Requirements Bottleneck
Developers ship faster than PMs can specify. Vague specs, manual decomposition, long clarification loops. The left side of the SDLC can't keep up.
Spec augmentation, interview/clarification, acceptance criteria generation, structured writeback into Jira.
Review Bottleneck
100x more code means 100x more to review. One model judging its own output is a monoculture failure. Humans can't scale review proportionally.
Cross-model review. Different model reviews than implements. Evidence-linked summaries with risk-tiered attention routing.
No Runtime Proof
"The code looks plausible" is not evidence. No browser validation. No screenshots. No DOM snapshots. Ship and pray.
First-class runtime validation. Browser testing via agent-browser. Screenshots, DOM, console, network traces as evidence artifacts.
Drift / Silent Decay
AI output looks done but quietly drifts from spec. Breaks contracts. Skips docs. Leaves tests stale. "Done" doesn't mean "correct."
Six drift auditors. Remediation loops. Blocker synthesis. Certify only when clean.
No Verifiability
Agents lie about completion. No certification artifacts. No evidence chain. No way to prove what was done, by which model, whether it actually passed.
Certification artifacts with model attribution, remediation count, runtime validation summary, integrity checksums.
No Harness Fits All
Claude reasons well. Codex parallelizes well. Cursor integrates well. Forcing one tool on every stage leaves quality on the table.
7 backend adapters. Backend selected per-task, per-stage. The right model for the right job, simultaneously.
Five stages. Every change.
Interview workers clarify requirements. 6 parallel scouts explore the codebase. Gap analysis catches cross-cutting risks. Synthesis generates dependency-gated task graphs optimized for parallel execution.
Structured specs, not vague prompts. Tasks decomposed for maximum safe parallelism.
Workers code in isolated git worktrees — one per task, parallel across the dependency graph. Any backend: Claude, Codex, Gemini, Cursor, or your own.
No file conflicts. Full codebase context. Backend-agnostic execution.
A different model reviews the diff against the original spec. SHIP or NEEDS_WORK with focus-point ranking, risk-tiered policies, and cited evidence. Feedback loops until SHIP.
Cross-model adversarial review. Not self-grading. Cited analysis, not "LGTM."
When upstream changes affect interfaces, downstream task specs are automatically updated. Keeps dependent tasks accurate as the codebase evolves during the run.
No stale specs. No drift. No surprise integration failures.
FIFO queue with auto-rebase, AI conflict resolution, and push-before-done semantics. 6 drift auditors certify the epic. Evidence chain with model attribution.
Clean history. Conflict-free integration. Certified output with audit trail.
Review isn’t optional. It’s structural. Every change passes through adversarial review before it touches your codebase. A different model reviews than implements — cross-model verification catches what self-review misses.
The foundry floor.
Four stages. Tasks move in parallel. Cross-model review is structural, not optional. Watch the machine run.
Specs in. Merged PRs out. Everything between is orchestrated.
Plan & dispatch
Epic parsed into dependency-gated task graph
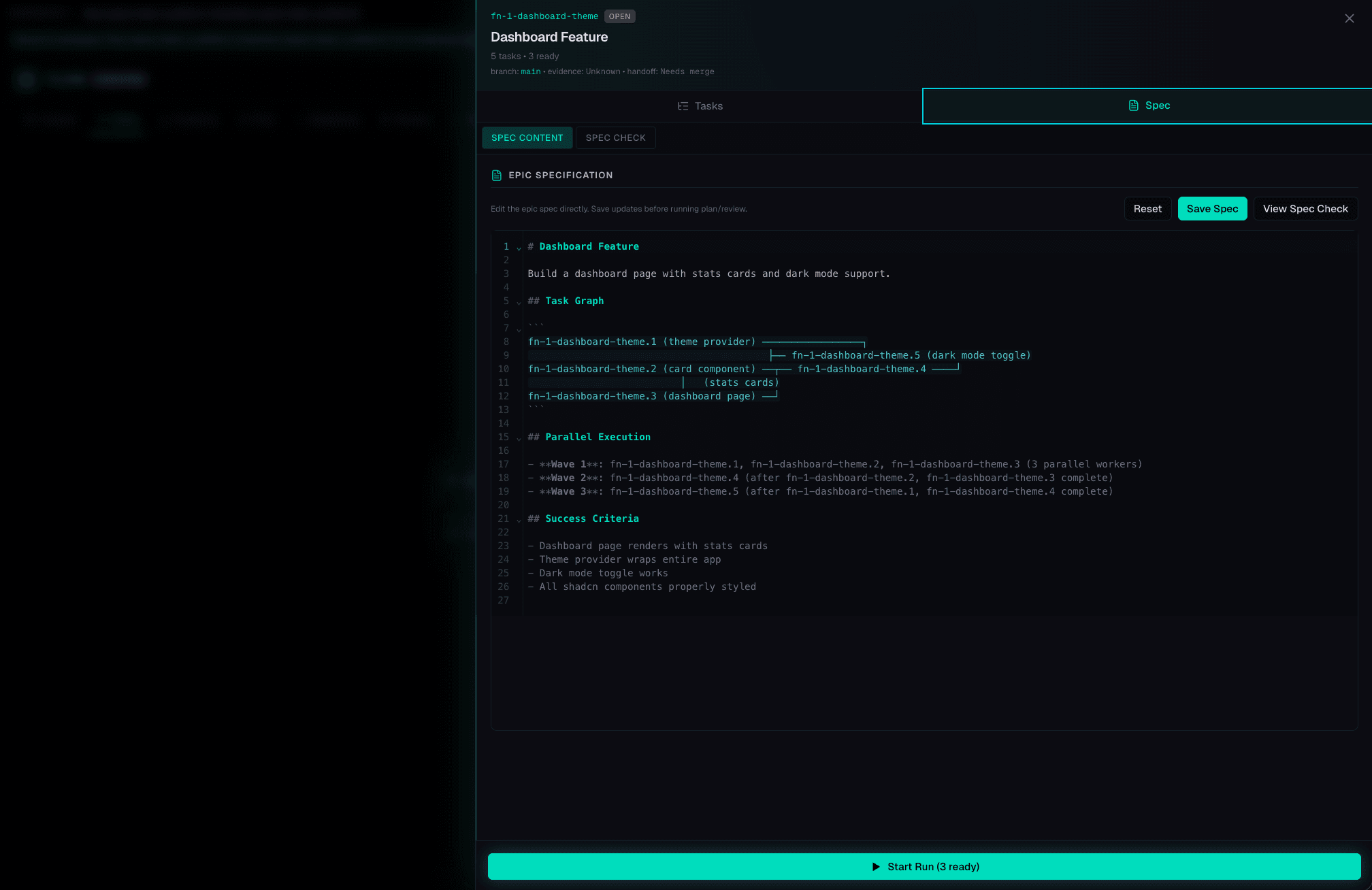
Five stages. Zero human intervention. See the pipeline run.
Request Early AccessNot just for developers.
The left side of the SDLC, accelerated.
Developers ship faster than PMs can specify. MergeFoundry closes the gap. PMs and POs write requirements in natural language — MergeFoundry interviews, structures, and produces execution-grade specs that flow directly into the pipeline. For frontend-heavy streams, a Stitch-style DESIGN.md can ride alongside the spec as an agent-readable design contract. Full integration with the tools your team already uses.
Import epics, sync status, write back artifacts
Issues, PRs, branch management, handoff publishing
Issue import, status sync, bidirectional updates
Import from where you plan. Write back to where you collaborate. MergeFoundry normalizes work internally and keeps external systems in sync.
Spec Augmentation
Rough requirements in natural language go in. MergeFoundry interviews, clarifies edge cases, surfaces missing acceptance criteria, and produces execution-grade specs.
Interview Workers
Interactive questionnaires that ask the right questions: What should happen on error? What contracts can't break? What are the edge cases? Not prompt engineering — structured requirement elicitation.
Acceptance Criteria Generation
Every task gets testable acceptance criteria derived from the interview. Reviewers check against these criteria. Auditors verify compliance. The spec is the contract.
Design Contracts
For UI-heavy work, MergeFoundry can also consume a Stitch-style `DESIGN.md` so layout, component, spacing, and visual rules become part of the planning contract instead of getting lost in prose.
Structured Writeback
Results flow back to where your team already works — Jira tickets updated, GitHub PRs published with evidence packages, Linear issues synced. No copy-paste. No context switching.
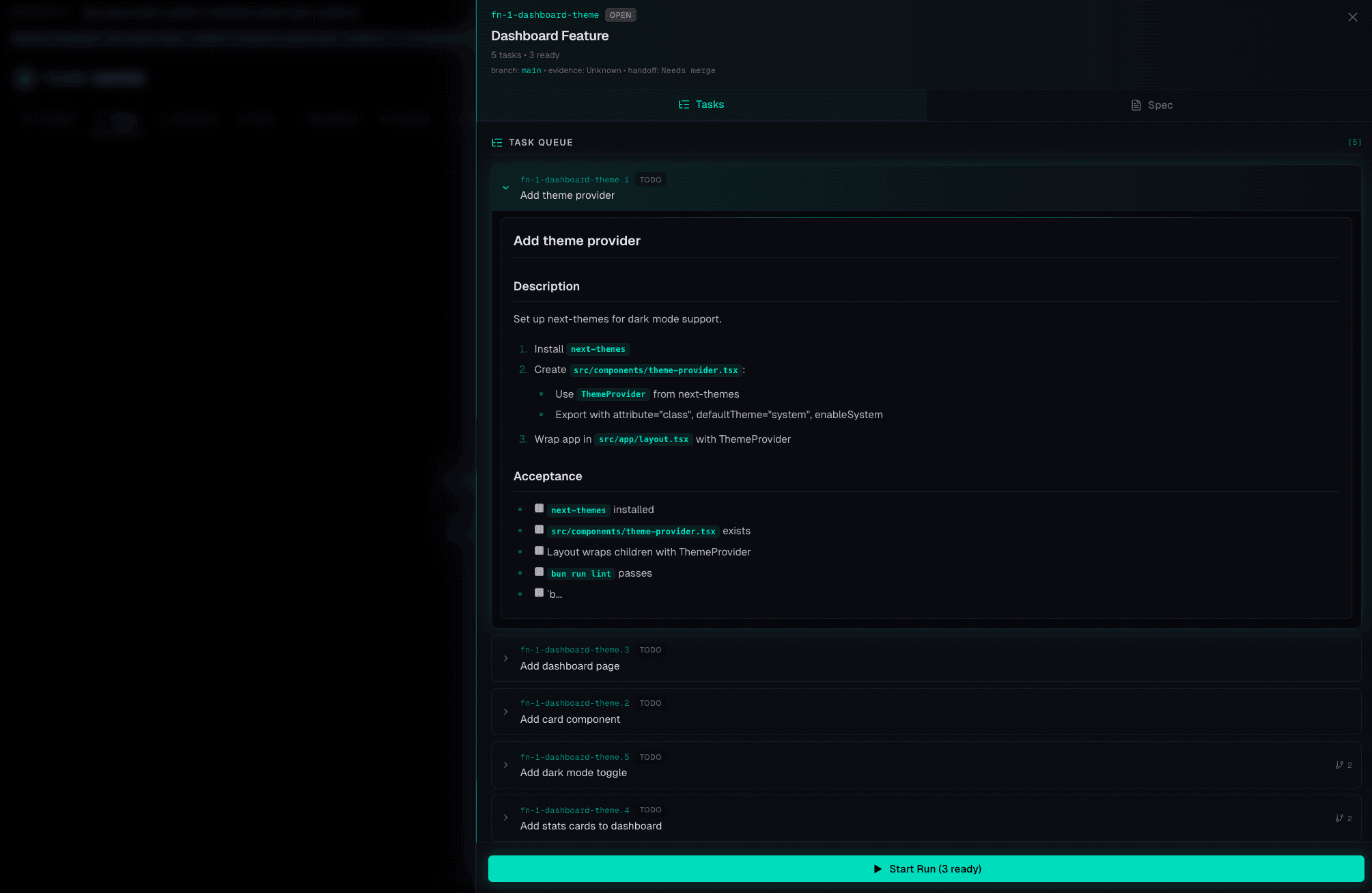
Requirements in.
Executable task graphs out.
PMs can’t specify fast enough. MergeFoundry closes the gap. Interview workers clarify requirements, 6 parallel scouts explore the codebase, gap analysis catches what individual scouts miss, and synthesis generates dependency-gated task graphs with acceptance criteria. A Stitch-style DESIGN.md can also feed planning when frontend/design rules matter. Cross-model plan review validates before a single line is written.
$ mf plan interview fn-1-auth-overhaul $ mf plan generate fn-1-auth-overhaul $ mf plan review fn-1-auth-overhaul
Interview
Interactive questionnaire clarifies requirements, surfaces edge cases, generates acceptance criteria. PMs specify in natural language — MergeFoundry structures it into execution-grade specs.
Not prompt engineering. Structured interview that asks the right questions: What should happen on error? What are the edge cases? What contracts can't break? Output: normalized spec with acceptance criteria, dependency mapping, and file targets.
Scout
Planning scouts explore the codebase — repo context, implementation patterns, documentation, epic dependencies, doc gaps, team memory, and optional design-system context when `DESIGN.md` is present. Each produces findings with evidence and risk assessments.
Scouts run on fast-tier models for speed. Each scout has a strict output contract: summary, key findings, evidence (file refs), risks/unknowns, recommendations, and handoff notes for synthesis. Design-system scouting turns tokens, component rules, and layout constraints into planning input instead of leaving them as vague visual intent.
Gap Analysis
Cross-scout synthesis identifies critical gaps, conflicting findings, and risk hotspots. Generates a validation checklist for the plan.
Not just concatenation. The gap analyzer cross-references scout outputs, identifies contradictions, flags risks that no individual scout caught, and produces a focused brief for the synthesis phase.
Plan Synthesis
Generates dependency-gated task graph from scout findings + gap analysis. Each task gets a structured spec with acceptance criteria, file targets, and dependency links.
Output: executable task graph with parallel groups, critical path identification, and per-task specs. Tasks reference specific files and acceptance criteria — not vague descriptions.
Plan Review
Cross-model review of the generated plan. A different model (default: Opus) reviews the plan for completeness, risk, and architectural soundness. SHIP or NEEDS_WORK with cited feedback.
Same adversarial review philosophy as code review, applied to planning. The reviewer checks: Are edge cases covered? Are dependencies correct? Is the task decomposition right-sized? Are acceptance criteria testable?
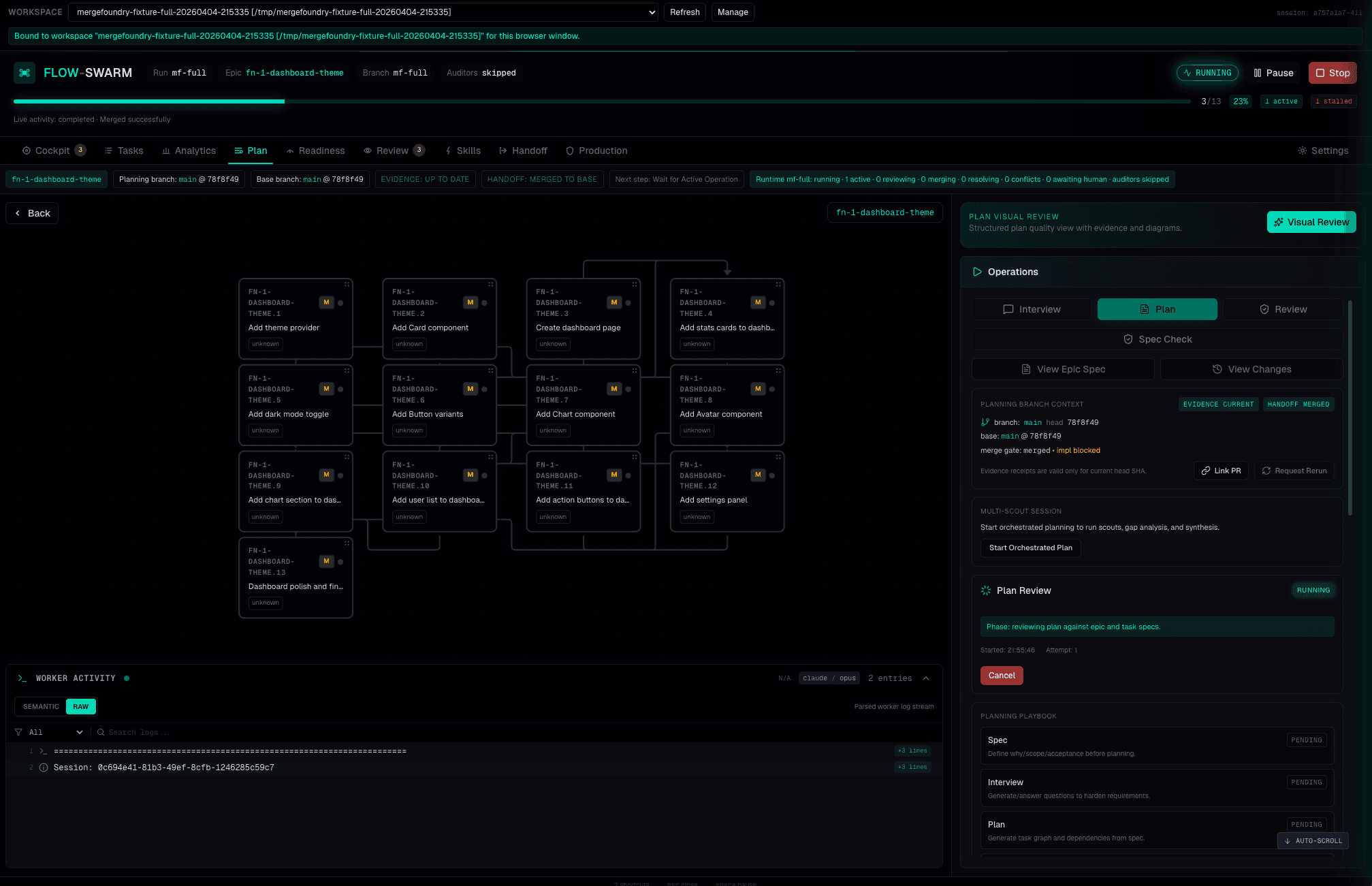
Not “LGTM.”
Cited analysis with evidence.
DORA 2025 found teams spend 91% more time on review. MergeFoundry compresses that. Every review produces a structured artifact with focus-point ranking, risk-tiered policies, structural analysis, and decisions with specific file and line citations. The reviewer doesn’t approve — it produces evidence.
Focus-Point Ranking
Every review produces ranked focus points — not a wall of comments. Each point has a priority (critical/high/medium/low), a numeric score, cited evidence with file references, and specific reasons. Reviewers orient on what matters, not what changed.
Risk-Tiered Policies
File paths map to risk tiers. Changes to src/core/**, auth/**, migrations/**, and *.sql get high-risk treatment — re-run verification gates even after initial pass. Docs and tests get low-risk fast-path. Configurable per-repo.
Review Compression
AI synthesis compresses raw diffs into structured artifacts: what happened, structural implications, layering observations, risk-dominant paths, and decisions with cited file:line references. Not "LGTM" — cited analysis with evidence chain.
Cross-Model Adversarial Review
The review model is always different from the implementation model. Claude implements, Gemini reviews. Different training data, different blind spots. Anti-monoculture at the architectural level.
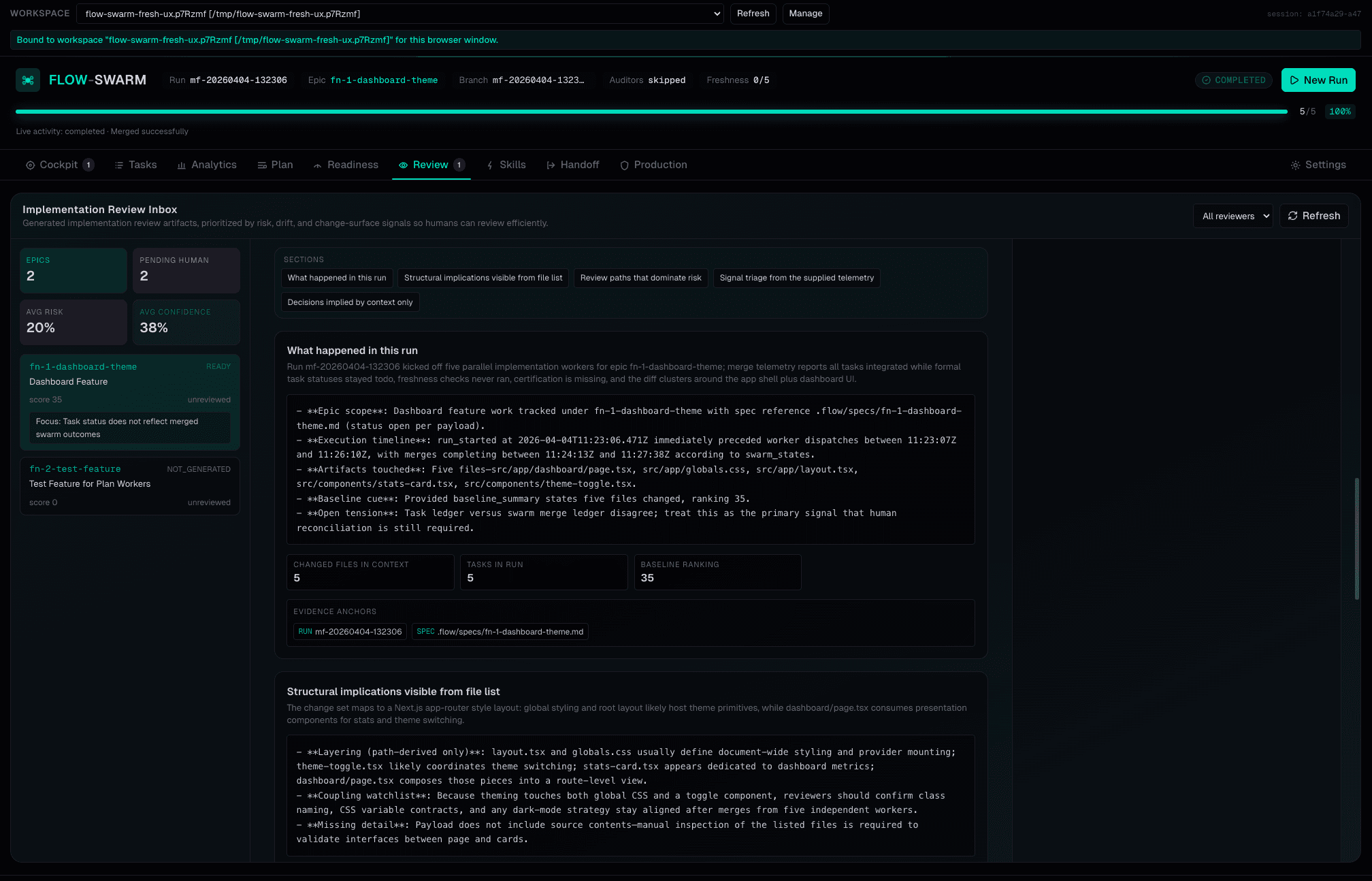
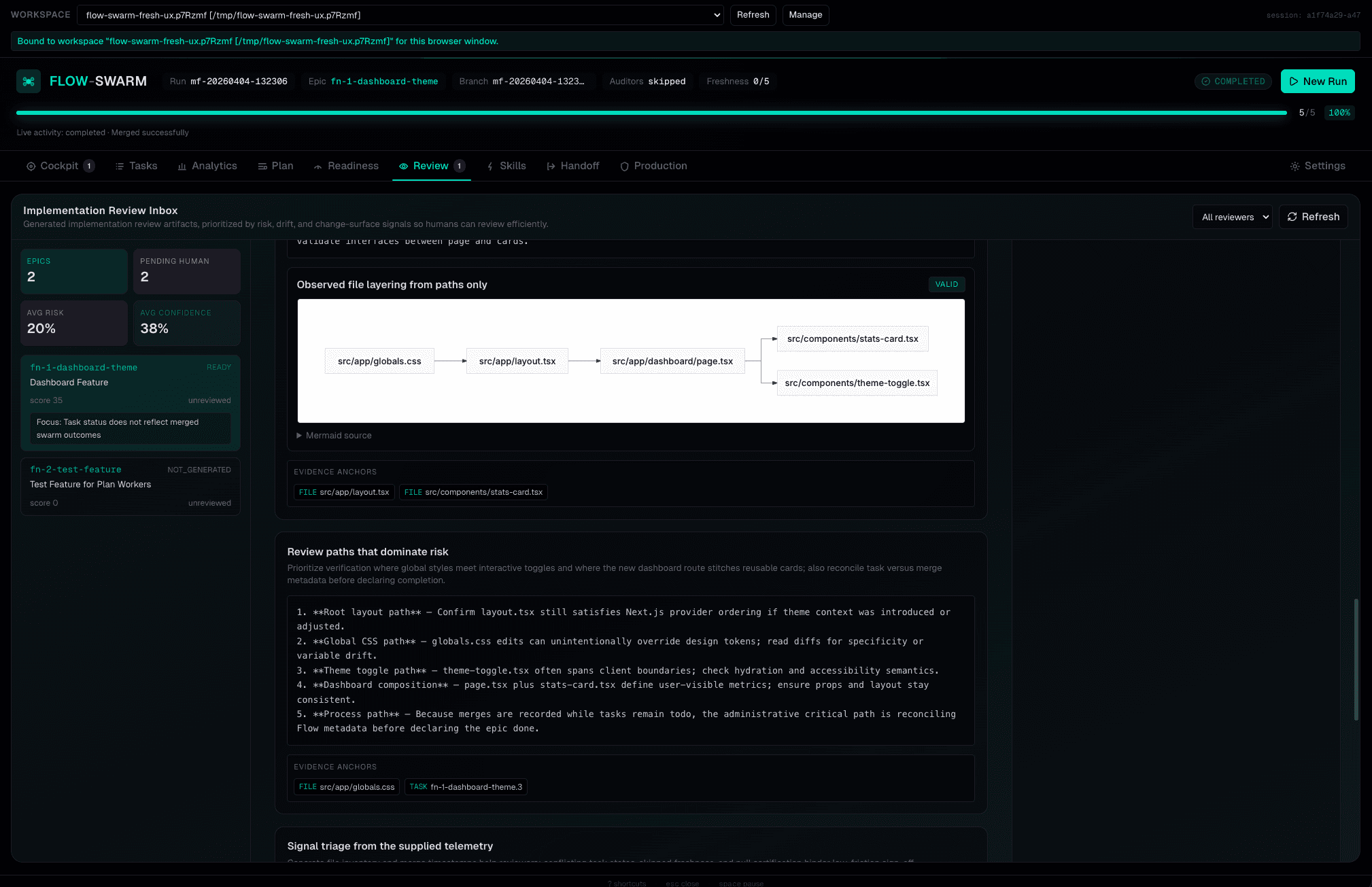
“Done” doesn’t mean correct.
Certification does.
After all tasks merge, six drift auditors verify nothing was silently broken. Each auditor produces a structured verdict with drift score, cited evidence, and remediation instructions. Blocking findings trigger automatic remediation loops. Certification artifacts provide a durable evidence chain: what was done, by which model, and whether it actually passed.
Detects API/public contract breakage. Additive exports are advisory; breaking changes block.
Compares implementation against epic and task intent. Catches silent divergence from requirements.
Verifies documentation matches shipped behavior. Catches stale READMEs, outdated setup guides.
Ensures release notes exist for shipped changes. Non-blocking when repo has no changelog convention.
Checks that architectural decisions are documented. Undocumented design choices get flagged.
Verifies test coverage for changed behavior. Missing tests for new code paths block by default.
Remediation Loop
Not just flag-and-forget. Blocking findings trigger automatic fix → re-gate → re-audit cycles.
Auditors fan out in parallel, each producing structured verdicts with drift scores (0-100) and cited evidence
Blocker synthesis deduplicates findings, classifies advisory vs blocking, and produces a prioritized remediation list
Auto-spawns remediation workers using the impl backend. Workers fix blocking findings and commit changes
Repo-native gates re-run (lint, typecheck, test). Auditors re-run on the remediated code. Loop until clean or max attempts
Certification artifact emitted with aggregate drift score, model attribution per stage, remediation count, and integrity checksum
{ "epic_id": "fn-1-auth-overhaul", "certified_at": "2026-04-04T14:32:00Z", "aggregate_drift_score": 4, "auditor_count": 6, "remediation_count": 1, "model_attribution": [ { "stage": "impl", "backend": "composer-2-fast" }, { "stage": "review", "backend": "gpt-5.4-high" }, { "stage": "auditor", "backend": "opus-4.6" } ], "checksum": "sha256:a3f8..." }
“Tests pass” is not proof.
Runtime evidence is.
MergeFoundry launches your app, navigates it with agent-browser, captures screenshots, DOM snapshots, console logs, and network traces as first-class evidence artifacts. Not simulated — actual browser execution with governed templates. When a repo carries a DESIGN.md contract, runtime validation can also use it for design-system conformance checks.
Deterministic smoke check — does the page load, hydrate, render without errors?
Evidence capture — screenshots, DOM snapshots, console logs at specific routes
Bounded exploratory review — AI navigates the app, finds bugs, reports findings
Exploratory review with video recording — visual regression evidence
Before/after comparison — diff screenshots and accessibility trees
Performance profiling — Chrome DevTools traces as evidence artifacts
CLI command execution and exit code verification
Full session transcript capture with structured output
AI-driven CLI exploration with finding classification
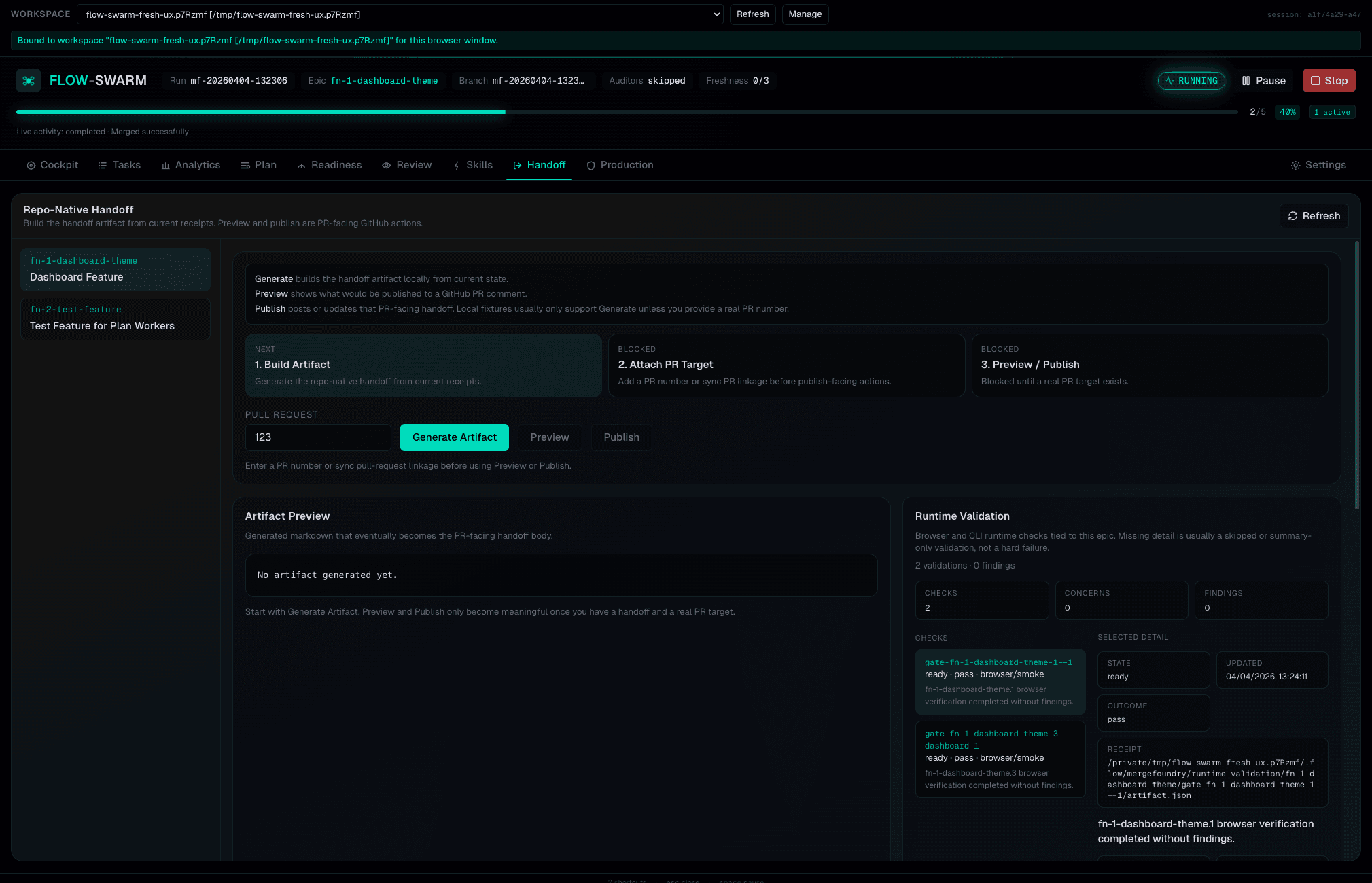
Isolated worktrees.
Conflict-free integration.
During planning, task decomposition optimizes for maximum safe parallelism — structuring work so independent tasks execute simultaneously. Each worker gets its own isolated git worktree. The merge queue handles integration: FIFO ordering, auto-rebase, AI conflict resolution with deterministic guardrails, and push-before-done semantics. Every merge is verified — conflict markers cleared, remote HEAD changed, Flow state finalized.
AI resolver attempts resolution. Unresolved conflicts block as conflict status. No human escalation.
AI resolver attempts first. Unresolved conflicts park as awaiting_human for operator intervention.
Unresolved conflicts immediately stop the run. Maximum safety, minimum autonomy.
1. Merge — task branch → run branch 2. Push — merge commit is source of truth 3. Flow completion — mark task done in spec 4. Finalization commit — commit spec update 5. Push finalization — push final state
All merge, rebase, and conflict resolution operations run in a dedicated integration worktree (.worktrees/mf-integration-*), not your primary checkout. Your working tree stays clean for edits. No dirty-state interference. Deterministic conflict context.
Every change planned, reviewed, certified, and merged. Autonomously.
Request Early AccessUse every model where it’s strongest.
Every backend serves the same purpose — headless control of a coding agent CLI. Different organizations have different subscriptions, different model access, different cost profiles. MergeFoundry uses them all. Assign any backend to any pipeline stage. Optimize for cost, capability, or model availability.
backends: implement: composer-2-fast review: gpt-5.4-high (via codex) sync: opus-4.6 (via claude) resolve: opus-4.6 (via claude)
One harness implements. A different one reviews. Mix and match based on what your team has access to.
Anthropic models via Claude Code CLI harness
OpenAI models via Codex CLI harness
Any Cursor-available model via Cursor CLI harness
Google models via Gemini CLI harness
GitHub-hosted models via Copilot CLI harness
Pico models via Pi CLI harness
Any agent CLI via the adapter interface
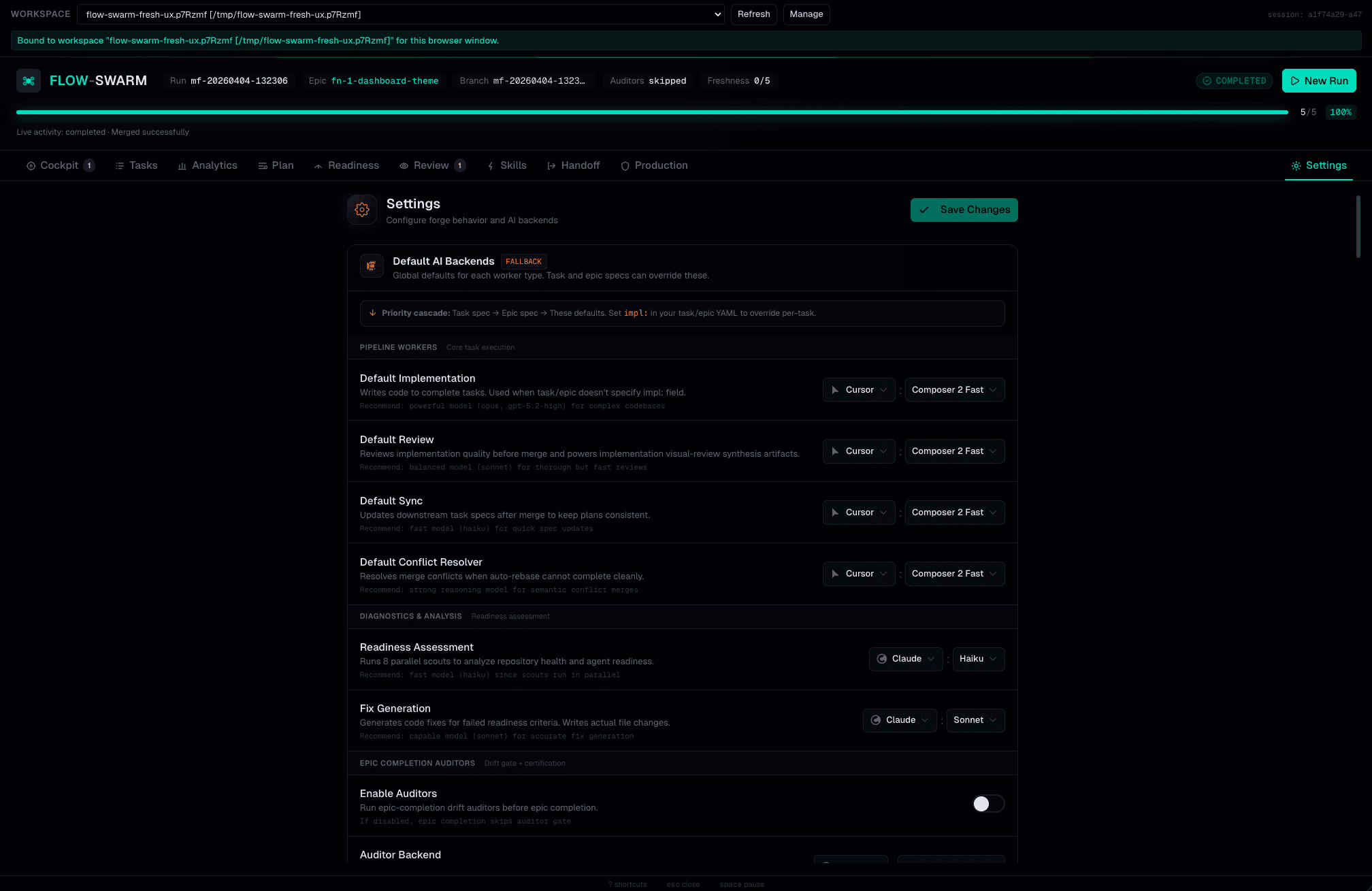
Coding is the easy part.
MergeFoundry handles the rest.
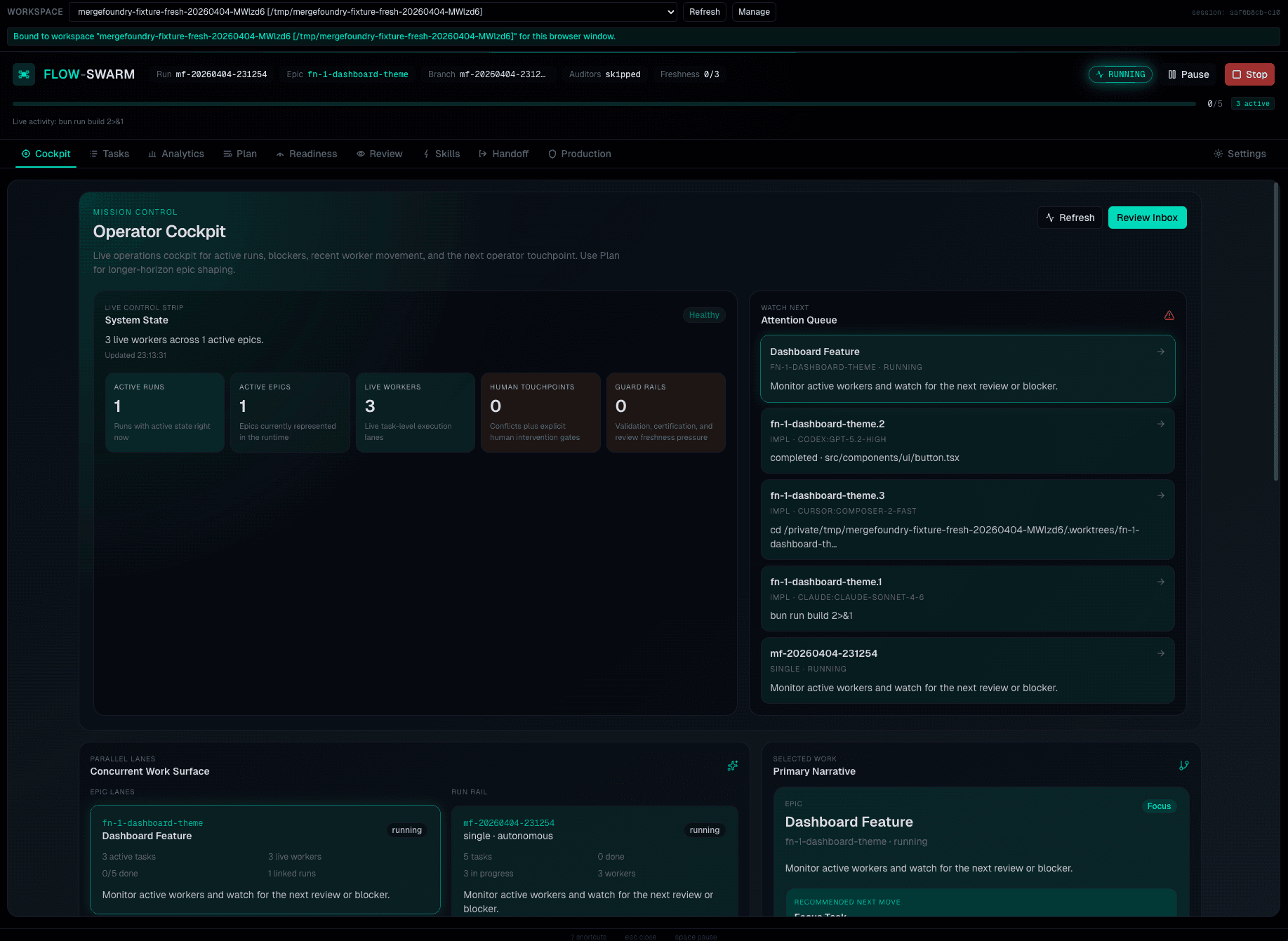
Mission Control
What's active, what's blocked, what needs attention. System state cards, attention queue, worker rail, concurrent work surface. Attention routing, not babysitting.
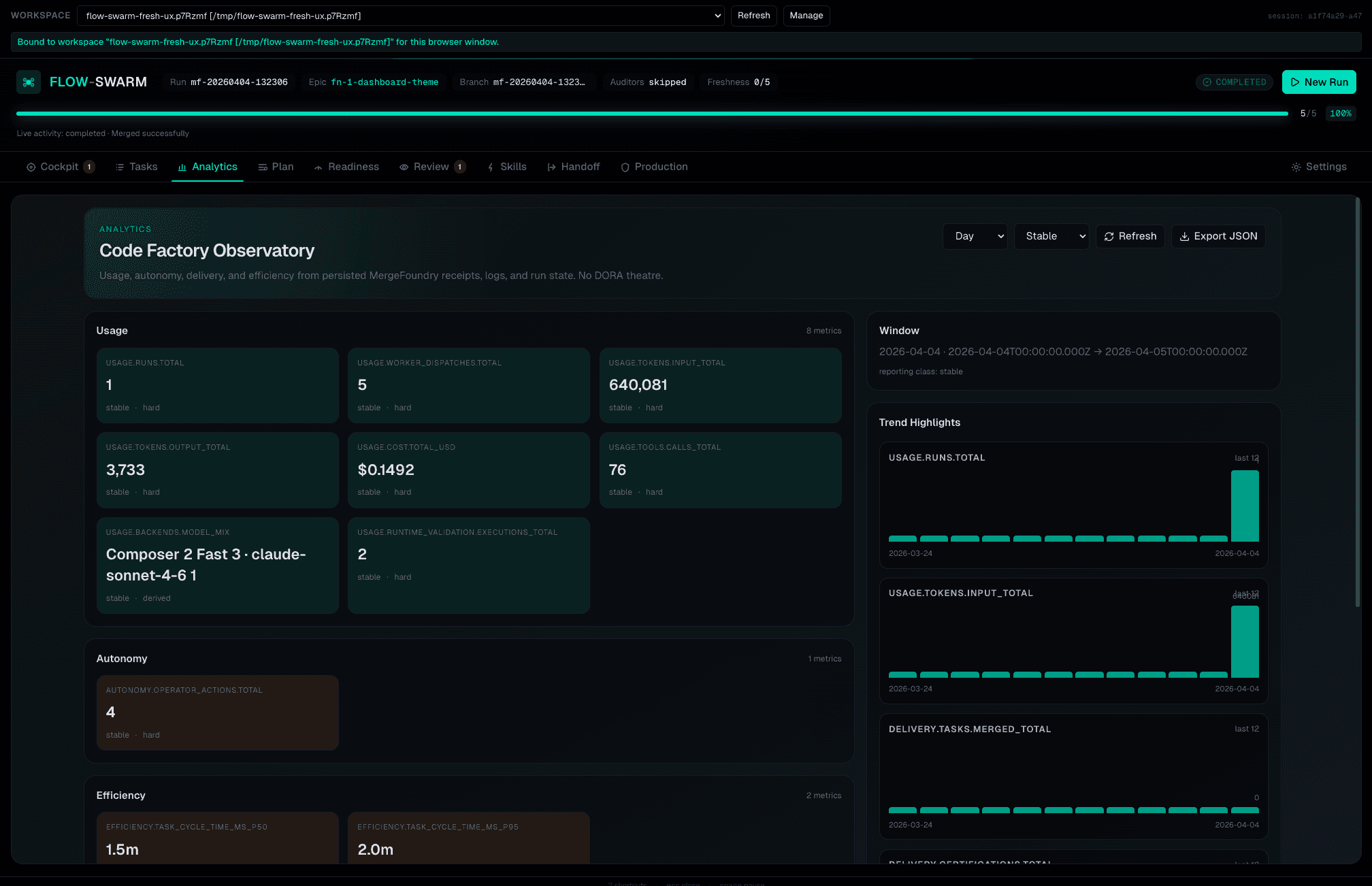
Code Factory Observatory
Usage, autonomy, delivery, efficiency metrics. Runs, costs, tokens, model distribution. DORA-adjacent — no theatre.
Epic Certification
Contract-drift, spec-drift, doc-drift, changelog-drift, ADR-drift, test-drift. Remediation loops until clean. Certification artifacts with evidence chain.
Runtime Validation
Screenshots, DOM snapshots, console logs, network traces. Evidence flows into review, certification, and handoff. Not just "tests pass" — runtime proof.
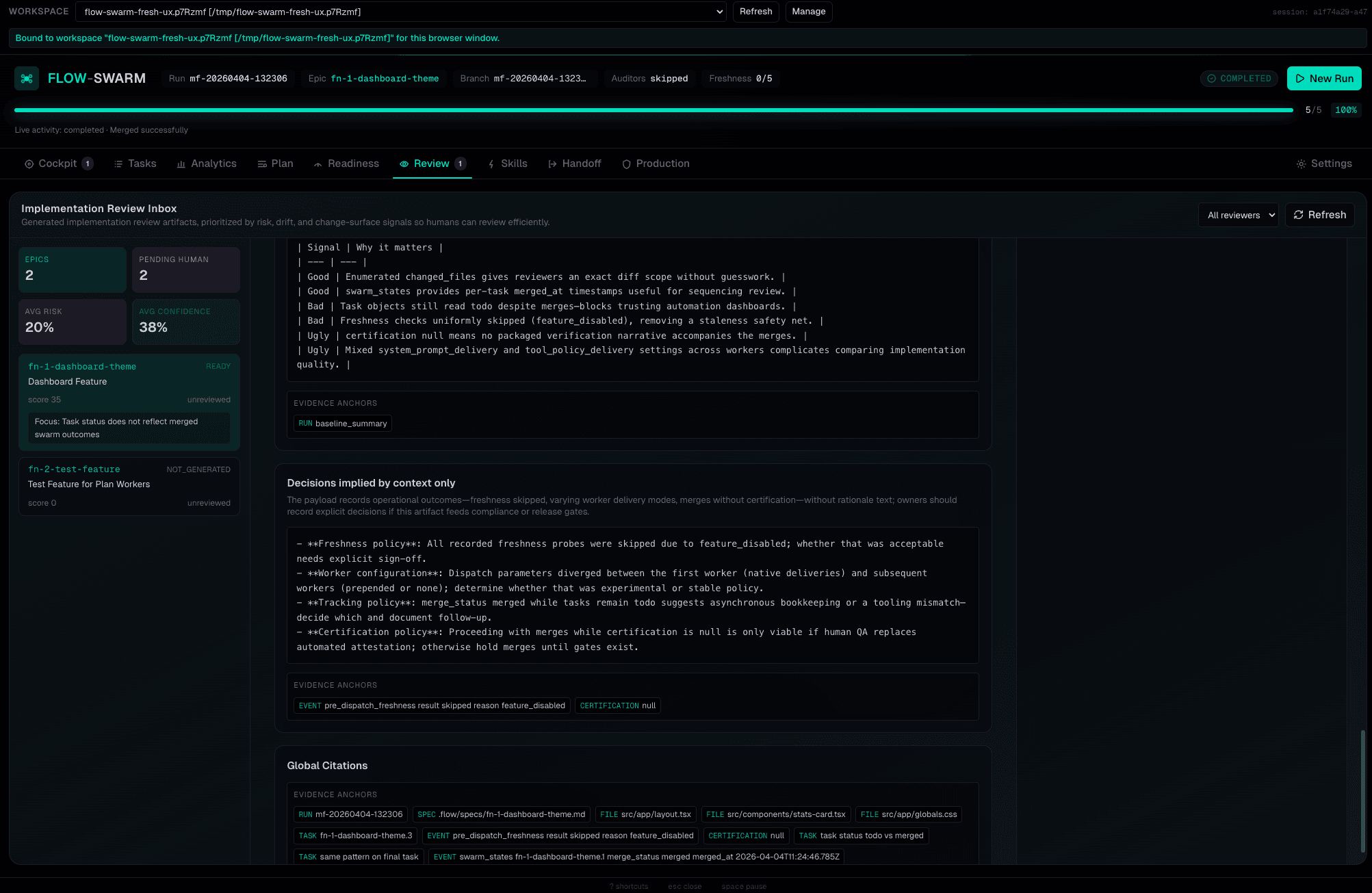
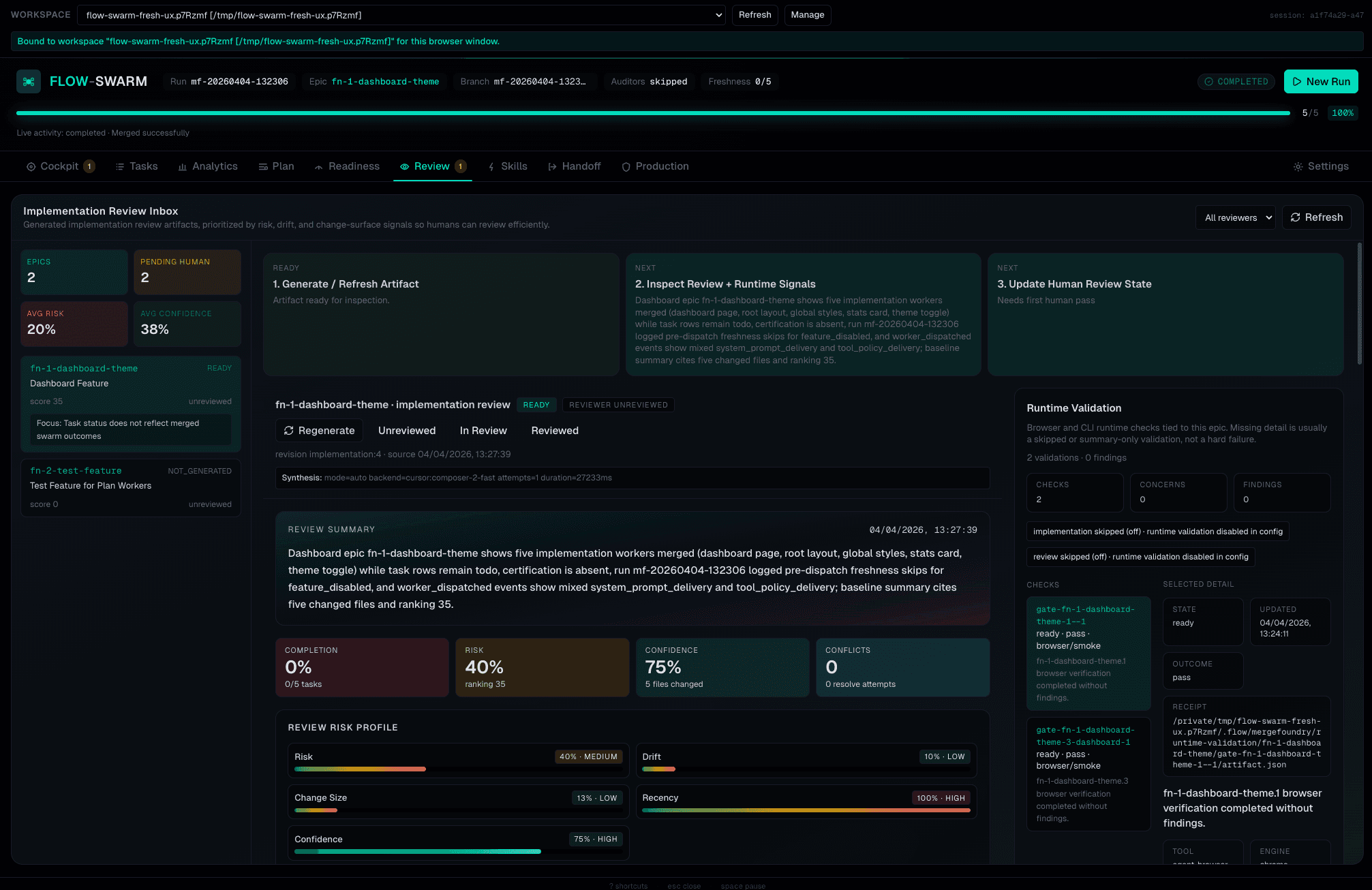
AI Review Intelligence
The reviewer doesn't just approve — it produces structural analysis, layering observations, risk-dominant paths, and decisions with specific file and line citations.
Spec-Driven Planning
Interview workers clarify requirements. 6 parallel scouts explore the codebase. Gap analysis synthesizes cross-cutting risks. Plan review validates before a single line is written.
8 pillars. 48 criteria.
Know exactly where you stand.
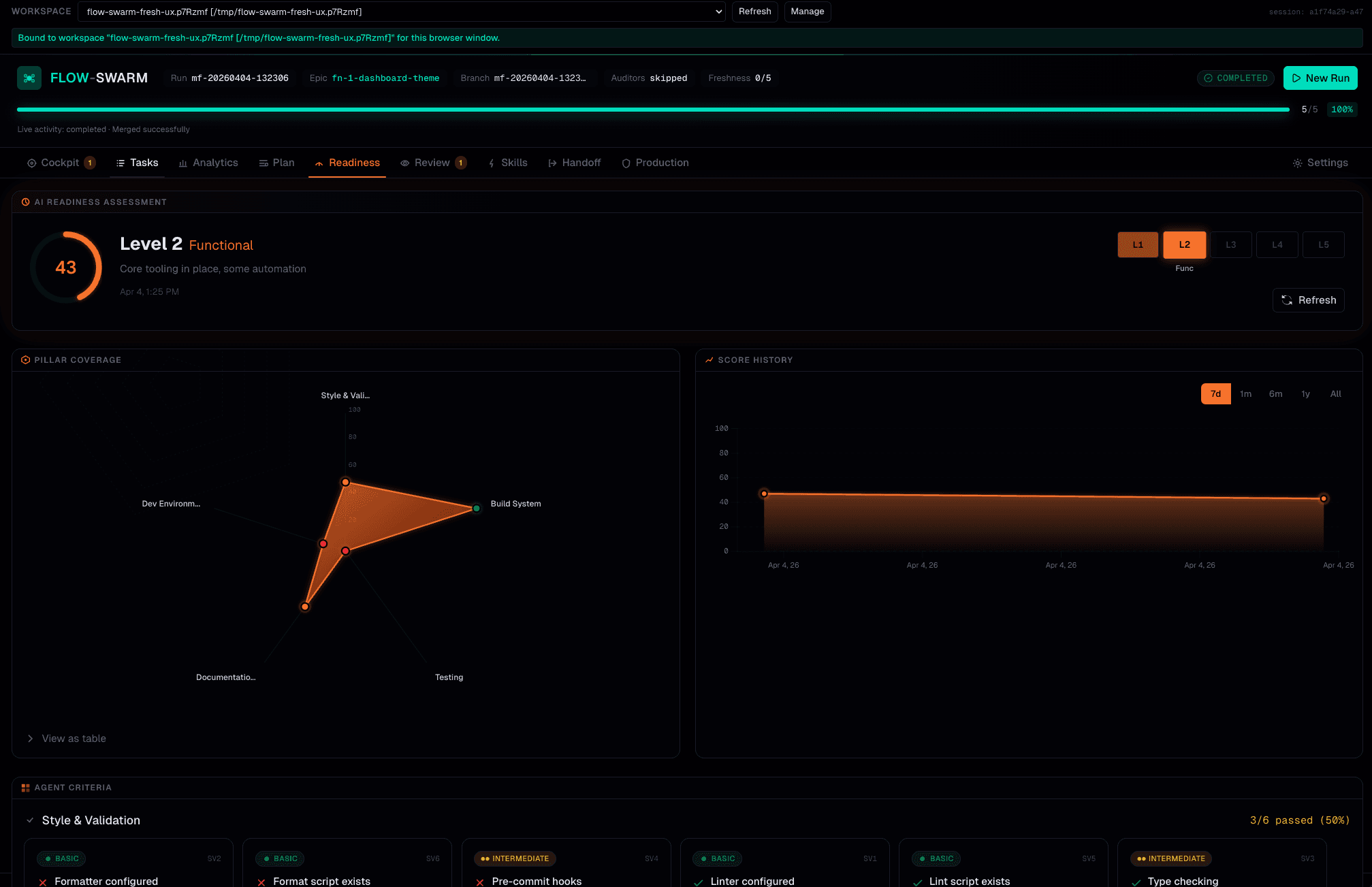
Before your first run, MergeFoundry assesses your codebase across 8 pillars with 48 individual criteria. 8 parallel scouts — one per pillar — analyze your repo and produce a maturity score from L1 (Minimal) to L5 (Autonomous). Agent readiness scouts can auto-fix issues. Production readiness scouts report only.
Linter, formatter, type checking, pre-commit hooks
tooling-scoutBuild tool, dev command, lock file, monorepo tooling
build-scoutTest framework, runnable tests, coverage config, E2E
testing-scoutREADME, CLAUDE.md/AGENTS.md, setup docs, architecture
docs-scout.env.example, runtime pinning, Docker/devcontainer, IDE config
env-scoutLogging, tracing, metrics, health checks
Branch protection, CODEOWNERS, secrets scanning
CI/CD, PR templates, issue templates, automation
≥85% agent, all pillars ≥80%
≥70% agent, all pillars ≥60%
≥50% agent, all pillars ≥40%
≥30% agent score
Below Functional
$ mf readiness Agent Readiness: 78% (L4 Optimized) Prod Readiness: 62% Overall: 73% Pillar Scores: ✓ Style & Validation ····· 100% ✓ Build System ··········· 83% ! Testing ················ 50% ✓ Documentation ·········· 83% ✓ Dev Environment ········ 67%
Measure the factory.
No DORA theatre.
Four dimensions of operational truth: usage, autonomy, delivery, efficiency. Every metric is classified as stable (backed by persisted state, safe for export) or advisory (heuristic, must stay labeled). No deployment frequency. No change failure rate. No individual productivity ranking. Factory metrics for factory operators.
MergeFoundry explicitly excludes DORA metrics (deployment frequency, change failure rate, MTTR), business-value attribution, and individual engineer productivity ranking. Advisory metrics are labeled as such and cannot be mistaken for ground truth. The observatory measures the factory, not the people.
The factory gets smarter.
Under your control.
After each epic, MergeFoundry extracts skill candidates from review focus points, file patterns, and worker telemetry. But skills don’t auto-apply. Every candidate goes through explicit operator review and promotion. No uncontrolled memory drift. No silent behavioral changes. Governed learning with provenance.
Distilled from the top focus points of implementation reviews. Captures what the reviewer flagged most — security patterns, edge cases, API contract checks — as reusable checklists for future workers.
Identifies commonly co-modified file groups from review evidence. When one file in the cluster changes, workers get guidance about the others. Prevents "forgot to update the tests" drift.
Captures which model/role combinations produced the best outcomes for specific task types. Encodes institutional knowledge about backend routing.
Auto-extracted from review artifacts, certifications, and worker logs after each epic
Operator reviews the skill draft — title, summary, trigger hint, and markdown content
Written as SKILL.md to the repo. Injected into matching worker prompts on future runs
Operator decides the pattern isn't worth encoding. Archived with reason
$ mf skills list $ mf skills show sk-a3f8 $ mf skills promote sk-a3f8 --path skills/auth-review.md $ mf skills reject sk-b2c4 --reason "too specific"
Every skill candidate carries full provenance: source epic, source run, review revision key, certification checksum, event count, and evidence anchors. You know exactly where each skill came from and can trace it back to the original review or certification that produced it.
From assistant to code factory.
Meet your team where they are. Scale autonomy as trust grows.
No AI
Copilot, inline suggestions
Multi-file edits, agent-assisted
Agentic SDLC, review-gated automation
Mission Control, attention routing, measurable delivery
Fully autonomous, minimal human in loop
Most teams are stuck at L1–L2 — autocomplete and agent-assisted edits.
MergeFoundry puts you at L3–L4 on day one.
Review-gated automation, Mission Control, measurable delivery — immediately. And MergeFoundry is the first system designed to reach L5: lights-out dark factory.